晓谈数据工程 数据存储、数据处理与存储支持服务解析
数据工程作为现代数据驱动决策的核心支撑,其三大支柱——数据存储、数据处理以及存储支持服务,构成了企业数据生命周期的骨架。本文旨在深入探讨这三者的内在逻辑、技术演进与协同实践,为构建高效、可靠的数据基础设施提供参考。
一、数据存储:数据工程的基石
数据存储是数据工程的起点与归宿,其核心任务是为海量、多源、异构的数据提供持久化存放的物理或逻辑空间。随着数据规模与形态的演变,存储技术也经历了从传统关系型数据库到分布式、云原生存储的跃迁。
1. 存储介质与架构演进
从硬盘、SSD到内存与持久内存,存储介质的性能提升为数据访问速度带来了革命性变化。架构层面,集中式存储逐渐向分布式存储(如HDFS、Ceph、对象存储)演进,以满足可扩展性、容错性与成本控制的需求。云存储服务(如AWS S3、Azure Blob Storage)的普及,进一步降低了存储管理的复杂度。
2. 数据模型与存储格式
根据数据使用场景,存储模型需灵活适配。结构化数据常采用关系型数据库(如MySQL、PostgreSQL)或数仓(如Snowflake、BigQuery);半结构化与非结构化数据则倾向于NoSQL数据库(如MongoDB、Cassandra)或对象存储。存储格式的选择(如Parquet、ORC、Avro)直接影响数据处理效率,列式存储因优秀的压缩与查询性能,已成为分析型场景的主流。
二、数据处理:从原始数据到价值的转化器
数据处理是将原始数据转化为可用信息与知识的关键环节,涵盖数据清洗、转换、集成、分析与建模等步骤。其核心目标是提升数据质量、挖掘数据价值,并支撑上层应用。
1. 批处理与流处理双轨并行
批处理(如Apache Spark、Flink批模式)适用于对时效性要求较低的大规模历史数据分析,而流处理(如Apache Kafka Streams、Flink流模式)则应对实时数据流,满足监控、预警等即时决策需求。现代数据平台常采用Lambda或Kappa架构,实现批流一体融合处理。
2. 数据处理框架与生态
开源生态蓬勃发展,Hadoop、Spark、Flink等框架提供了强大的分布式计算能力。云原生数据处理服务(如AWS Glue、Google Dataflow)通过托管服务简化了运维。数据处理正朝着自动化(AutoML)、智能化(AI增强数据质量)方向发展,减少人工干预成本。
三、存储支持服务:数据高效流动的保障
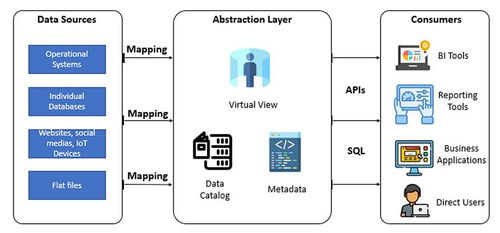
存储支持服务是连接数据存储与处理的“粘合剂”,确保数据在存储、计算、应用间高效、安全、可靠地流动。它涵盖数据管理、元数据管理、数据安全与治理等关键支撑能力。
1. 数据管理与元数据服务
数据目录(如Apache Atlas、DataHub)通过元数据管理,实现数据资产的发现、血缘追踪与影响分析,提升数据可发现性与可信度。数据生命周期管理(如分层存储、自动归档)则优化存储成本与性能平衡。
2. 数据安全与治理
在数据合规要求日益严格的背景下,存储支持服务必须集成加密(静态/传输中)、访问控制(RBAC、ABAC)、审计日志等功能。数据治理框架(如数据质量监控、主数据管理)确保数据在整个生命周期中的一致性、准确性与合规性,为数据价值释放保驾护航。
协同演进,构建韧性数据架构
数据存储、数据处理与存储支持服务并非孤立存在,而是相互依存、协同演进的有机整体。在云原生与AI驱动的趋势下,未来的数据工程将更加强调自动化、智能化与一体化。企业需根据自身业务规模、技术栈与成本考量,灵活选择与整合这三层能力,构建弹性、高效且安全的数据架构,从而在数据洪流中稳健航行,真正实现数据驱动的创新与增长。
如若转载,请注明出处:http://www.51xmlong.com/product/54.html
更新时间:2026-06-19 09:05:13