Python数据分析实战 抓取课工厂网站数据与深度分析
在数据驱动的时代,Python凭借其强大的库支持已成为数据分析和网络爬虫的首选工具。本文将以“课工厂”网站为例,详细介绍如何使用Python抓取网站数据,并进行数据处理、存储与分析的全流程实践,旨在为数据分析初学者和从业者提供一个完整的实战案例。
一、数据抓取:使用Python爬虫获取课工厂网站信息
- 环境准备与工具选择
- 安装Python 3.x版本,并配置好开发环境(如Jupyter Notebook或PyCharm)。
- 核心库安装:使用pip安装requests、BeautifulSoup、pandas、sqlite3等库。requests用于发送HTTP请求,BeautifulSoup用于解析HTML,pandas用于数据处理,sqlite3用于数据存储。
- 分析网站结构并设计爬虫策略
- 访问课工厂网站,通过浏览器开发者工具(如Chrome的Inspect)分析页面结构,确定目标数据(如课程名称、价格、讲师、评分等)所在的HTML标签。
- 设计爬虫流程:发送请求 → 解析响应 → 提取数据 → 存储数据。注意遵守robots.txt协议,并设置合理的请求间隔以避免对网站造成负担。
- 编写爬虫代码示例
- 使用requests库模拟浏览器请求,获取网页内容。
- 利用BeautifulSoup解析HTML,通过CSS选择器或find方法定位数据元素。
- 将提取的数据整理为字典或列表形式,便于后续处理。
二、数据处理与存储:清洗、转换并保存数据
- 数据清洗与预处理
- 使用pandas库将爬取的数据转换为DataFrame,方便进行结构化操作。
- 处理缺失值:对于空值或异常数据,可选择删除、填充或插值方法。
- 数据标准化:例如,将价格字符串转换为数值类型,或统一日期格式。
- 数据存储方案
- 本地存储:将DataFrame保存为CSV或Excel文件,便于快速查看和共享。
- 数据库存储:使用sqlite3或MySQL等数据库,实现数据的持久化和管理。例如,创建课程信息表,并将清洗后的数据插入表中。
三、数据分析:挖掘课工厂数据的价值
- 描述性统计分析
- 计算课程价格的平均值、中位数、标准差等,了解价格分布情况。
- 分析讲师授课数量排名,识别热门讲师。
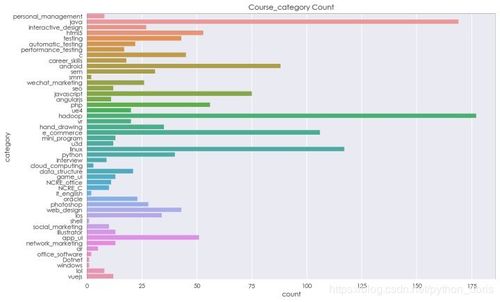
- 可视化展示:使用matplotlib或seaborn库绘制柱状图、饼图等,直观呈现课程类别占比或评分分布。
- 深入洞察与趋势发现
- 关联分析:探索课程价格与评分、讲师经验之间的关系。
- 文本分析:对课程描述进行关键词提取,了解热门主题趋势。
- 预测模型(进阶):基于历史数据,尝试构建线性回归模型预测课程受欢迎程度。
四、支持服务与优化建议
- 自动化与扩展性
- 将爬虫脚本部署为定时任务(如使用cron或APScheduler),实现数据自动更新。
- 考虑使用Scrapy框架提升大规模爬取效率,并集成代理IP应对反爬机制。
- 数据安全与合规性
- 确保爬虫行为符合网站使用条款,避免侵犯隐私或版权。
- 对存储的数据进行加密备份,防止泄露。
- 服务化应用
- 将分析结果通过Flask或Django框架构建Web应用,提供数据查询和可视化界面。
- 结合API服务,为其他系统提供课程数据支持。
通过本实例,我们展示了Python在数据分析领域的强大能力——从数据抓取到存储,再到深度分析,形成了一个闭环流程。课工厂网站的数据分析不仅帮助用户理解课程市场,也为优化课程推荐和服务提供了数据支撑。随着技能的提升,读者可进一步探索机器学习、实时分析等高级应用,让数据真正驱动决策与创新。
如若转载,请注明出处:http://www.51xmlong.com/product/58.html
更新时间:2026-06-19 12:30:18