刘奇谈如何构建一个NewSQL数据库 数据处理与存储支持服务
在当今数据驱动的时代,传统关系型数据库在处理海量数据和高并发场景时面临诸多挑战,而NewSQL数据库应运而生,它结合了NoSQL的扩展性和SQL的事务一致性。作为PingCAP的联合创始人,刘奇在构建TiDB这一开源的分布式NewSQL数据库方面积累了丰富经验。本文将基于刘奇的见解,探讨如何构建一个NewSQL数据库,重点关注数据处理和存储支持服务的关键要素。
一、NewSQL数据库的核心设计理念
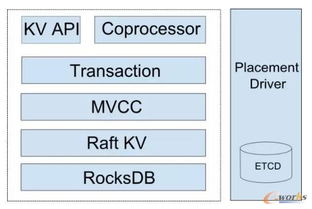
NewSQL数据库旨在解决传统数据库的痛点,如水平扩展性、高可用性和实时分析能力。刘奇强调,构建NewSQL数据库需遵循几个基本原则:采用分布式架构以支持线性扩展;确保ACID事务特性,保证数据一致性;整合数据处理与存储,实现高效服务。TiDB的成功实践表明,通过将计算与存储分离,数据库可以更灵活地适应云原生环境。
二、数据处理层的构建
数据处理是NewSQL数据库的核心,涉及查询优化、事务管理和并发控制。刘奇指出,TiDB采用了类似Google Spanner的架构,将SQL层与分布式存储层解耦。在数据处理方面,关键点包括:
- SQL解析与优化:使用基于成本的优化器(CBO)来提升查询性能,支持复杂的OLTP和OLAP负载。
- 分布式事务处理:通过两阶段提交(2PC)和乐观锁机制,确保跨节点事务的原子性和隔离性。
- 实时数据处理:集成流处理能力,例如通过TiDB Lightning和TiCDC工具,实现数据的实时同步和ETL流程,从而支持业务快速响应。
刘奇强调,数据处理层需要具备弹性,能够根据负载动态调整资源,这通常依赖于容器化和编排技术,如Kubernetes。
三、存储支持服务的设计
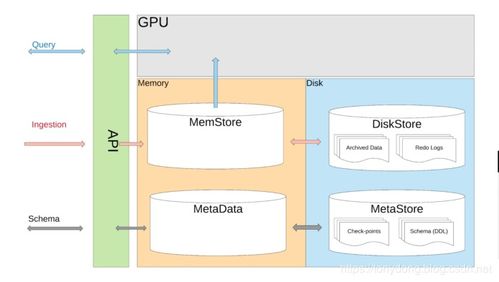
存储层是NewSQL数据库的基石,负责数据的持久化、复制和恢复。TiDB使用TiKV作为分布式键值存储引擎,刘奇分享了其设计思路:
- 分布式存储架构:采用Raft共识算法实现数据多副本一致性,确保高可用性和容错能力。数据自动分片(sharding)到多个节点,支持水平扩展。
- 混合存储引擎:结合行存储和列存储,优化不同工作负载。例如,TiFlash作为列存储引擎,加速分析查询,而不影响事务处理。
- 数据备份与恢复:提供快照和增量备份机制,并与云存储集成,实现数据的可靠持久化。刘奇提到,在构建存储服务时,需考虑数据本地化和网络延迟,以提升性能。
存储层还需支持多租户和资源隔离,这在云环境中尤为重要。TiDB通过命名空间和配额管理,确保不同业务的数据安全与性能隔离。
四、实际应用与挑战
刘奇在多个演讲中强调,构建NewSQL数据库不仅是技术问题,还涉及生态建设。例如,TiDB与MySQL协议兼容,降低了迁移成本;同时,社区贡献推动了工具链的完善,如监控工具Prometheus和可视化工具Grafana。挑战依然存在:
- 一致性权衡:在分布式系统中,平衡强一致性和性能是关键,TiDB通过优化Raft实现低延迟。
- 运维复杂性:自动化运维工具和AI驱动的调优可以帮助减轻管理负担。
- 未来趋势:刘奇认为,NewSQL数据库将更深度整合AI和云原生技术,例如通过机器学习优化查询计划,或利用Serverless架构实现按需计费。
结语
构建一个NewSQL数据库如TiDB,需要从数据处理和存储支持服务入手,注重分布式架构、事务一致性和生态整合。刘奇的经验表明,通过开源协作和持续创新,NewSQL数据库能够为企业提供可靠、可扩展的数据解决方案。随着技术演进,这种数据库将继续推动数据基础设施的变革,助力数字化转型。
如若转载,请注明出处:http://www.51xmlong.com/product/6.html
更新时间:2026-06-19 06:08:37